AI is perhaps humanity’s greatest innovation since the internet and has the potential to surpass it entirely. Leaders in the field predict that foundation models will cognitively outperform humans by 2027. These systems enable greater task automation, reduce reliance on human labor, and allow businesses to scale more efficiently. Everything we do will soon be AI-coded. As the cost of knowledge work declines to the cost of inference—the process where a trained AI model applies its learned knowledge to new data—AI is set to transform nearly every industry.
Inference workloads account for 50% of NVIDIA revenues and are likely to grow orders of magnitude within the decade. As such, Big Tech’s AI-driven capital expenditures have surged, rising from $160 billion in 2023 to $260 billion in 2024, with projections exceeding $300 billion in 2025. Microsoft alone is set to spend $80 billion on AI data centers next year. In 2015, Google, Meta, and Microsoft allocated 5-15% of their yearly revenues to capex, but by 2025, this is expected to rise to 15-30%. Microsoft CEO Satya Nadella emphasized being early to technological shifts, stating, “In tech, all the money is made in the 2-3 years around a phase shift. If you miss it, you’ve missed the value capture for decades.” The massive capex investments by the Mag 7 certainly reflect this urgency. However, big tech solutions are centralized and censored, heightening the importance of open-source and decentralized alternatives. Moreover, crypto’s ability to enforce digital property rights, incentivize development, and optimize coordination becomes increasingly valuable. In turn, AI enhances crypto by improving user experience and enabling more advanced applications. All in, there is an increasingly important and symbiotic relationship between crypto and AI.
From Infrastructure to (Crypto-Powered) Applications
As capital deployment explodes, the market is shifting its focus from aggressive investment to measurable returns, a transition exemplified by breakthroughs in training and inference from AI companies like DeepSeek. Specifically, DeepSeek’s R1 release accelerated AI decentralization by open-sourcing its models and efficiently training its V3 model on reduced-capacity H800 GPUs in just two months for under $6M, significantly less than GPT-4’s estimated $40M. Experts praised DeepSeek’s training and inference innovations, including MLA and MoE, its efficient chip utilization, and its ability to distill models into smaller form factors. Open-sourcing the model propelled DeepSeek’s app to the top of the Apple App Store, driving down both the cost of accessing top-tier models and the cost per inference token toward zero.
Spurred by developments like Deepseek, AI is shifting from its infrastructure to its application phase, on its way to the enterprise phase. In more detail, top AI labs like OpenAI have previously reinforced their moats by outspending competitors, effectively limiting competition to those with similar funding. In contrast, DeepSeek, constrained by capital, was forced to innovate at the model layer, an area where well-funded foundational labs have been less focused or less incentivized to focus on. As such, Deepseek’s emphasis on software optimization, as opposed to hardware optimization, is raising the importance of the application layer. As costs decline, value capture will increasingly come from applications built on LLMs rather than the models themselves. As such, we expect 2025 to be the year of AI agents and consumer apps, driving our focus on which crypto subsectors are best positioned to capitalize on this paradigm.
NVIDIA Data Center Revenue ($bn) by Quarter
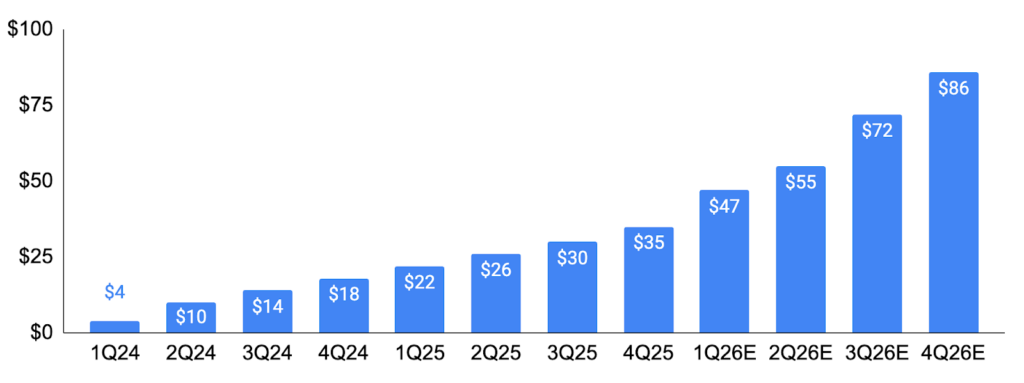
Source: NVIDIA, GSR. Note: 2026 figures are based on Wall Street estimates. Our quarters are based on Nvidia’s fiscal quarters, which differ from the calendar quarters.
A common question is why, and where, do crypto and AI interlap. The fact is AI doesn’t need blockchains. Closed-source AI operates well without them. However, just as finance doesn’t inherently need blockchains but becomes more efficient, transparent, and innovative with its integration, the same applies to AI. Blockchain transactions reduce reliance on intermediaries by leveraging cryptography for contract enforcement and ensuring universal access to information. Unlike traditional systems that require specialized third parties to manage contracts and gatekeep data, permissionless blockchains provide both transparently. This minimizes fees and allows applications to operate with greater efficiency and productivity. As such, crypto boasts some of the fastest-growing startups of all time. For example, Kamino employs 20 people and has $2b in TVL, while Pump.fun generated $100m in revenue in 217 days. In comparison, Cursor, one of the leading AI applications of 2024, reached $100m in roughly 365 days. Pump.fun’s growth is primarily driven by its ability to monetize its moat directly through speculation. By allowing anyone to seamlessly launch a token, Pump.fun crowdsourced liquidity and abstracted away complexity from the end user. Simply put, Pump.fun (and crypto) specializes in monetization and capital formation, whereas AI and social media specialize in distribution. Crypto’s coordination and monetization mechanisms can provide the necessary activation for AI applications and infrastructure to succeed.
Top Applications: Years from $1M to $100M ARR
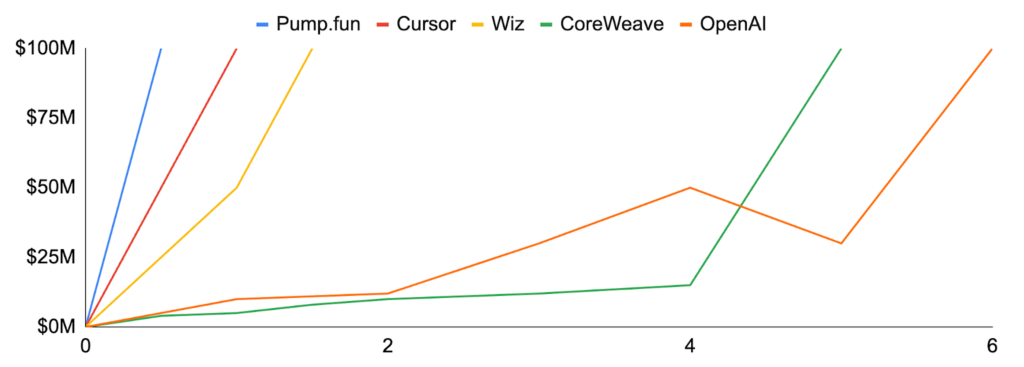
Source: Sacra, GSR.
We see several particularly compelling opportunities for crypto to integrate with and enhance AI. These include:
- Decentralized training, where distributed infrastructure can reduce costs and enhance training scalability
- Data, which allows for developers to monetize and trade proprietary data sets
- AI agents, which leverage blockchain for trustless execution and composability, and
- AI-based systems (e.g. Ritual, Bittensor), which align economic rewards with network participation and model contributions.
While this is not an exhaustive list, these subsectors are well positioned to drive near-term impact. As AI and crypto continue to converge, we expect these areas to serve as foundational pillars for reshaping both industries.
This is not intended to be a comprehensive AI report, but rather a spotlight on key sectors of an increasingly expansive market. The crypto and AI landscape is constantly evolving, and our goal is to outline our views on emerging trends, rather than provide a complete overview. While AI competitors will likely change over the next year, we believe that distributed training, data, AI agents, and AI-based systems will continue to thrive within this paradigm. Finally, this report assumes an intermediate level of knowledge of AI. For those looking for further background before reading, we highly recommend watching this explainer series here:
| Table of Contents |
|---|
| 1. Decentralized Trading |
| 1.1 Prime Intellect’s Intellect-1 |
| 1.2 Nous Research |
| 1.3 Gensyn & Pluralis Research |
| 2. Data |
| 3. Agents |
| 4. AI Specific Chains |
| 4.1 Ritual |
| 4.2 Bittensor |
Decentralized Training
AI model capabilities have advanced significantly in the last decade, largely due to increasing computational resources dedicated to pre-training and training. These improvements have led AI labs to rapidly expand training efforts, with compute usage rising approximately 4x yearly. Modern AI systems depend on clusters of co-located GPUs that require constant, high-speed communication to synchronize model parameters. This synchronization is critical for scaling LLMs, as individual machines process different data batches during training runs and must continuously share and aggregate model parameters (without synchronization, each GPU would develop a different version of the model). Thus, ensuring that all GPUs update to a consistent model version after each batch cycle is essential for maintaining accuracy. Co-locating GPUs optimizes this process, enabling faster synchronization and minimizing costs.
Exponential growth of computation in AI systems
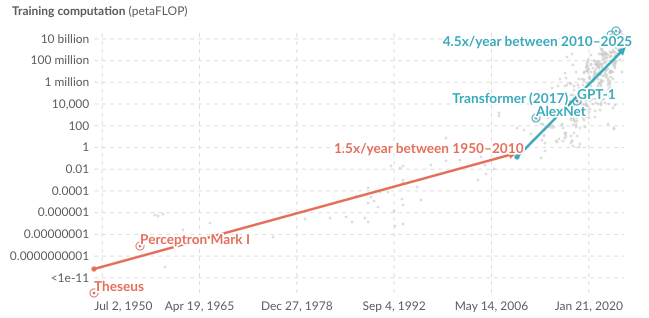
Source: Our World in Data, GSR. Note: Training FLOPs refer to the computational resources needed to train each model.
One downside of co-location, however, is that it makes scaling increasingly difficult, as adding more GPUs accelerates the burden on networking infrastructure. The only way forward in this paradigm would be to build ever-larger data centers. Expanding existing data centers becomes less feasible, forcing companies like Meta to construct new facilities on a massive scale—notably a 2GW data center in Louisiana—to accommodate the growing demand for GPUs. These limitations will inevitably reach a breaking point between power grid constraints, supply chain issues, and high infrastructure expansion costs.
Distributed training, on the other hand, is helping unlock the next wave of AI capabilities. Unlike traditional training, which relies on co-located hardware, distributed training utilizes compute resources spread across multiple data centers or warehouses, enabling greater flexibility and scalability. While distributed training methods are currently slower, costs are coming down rapidly, and leading players like Google and OpenAI are already implementing distributed training through fiber optics to connect GPUs across disparate data centers.
As a brief aside, it’s important to distinguish between distributed and decentralized training. Distributed training refers to training using hardware that is not co-located but managed within a centralized setting, such as across multiple data centers or campuses. In contrast, decentralized training involves geographically dispersed hardware where computational resources are managed without a central server. This allows anyone to contribute compute resources to the network and process training data. The primary distinction is that decentralized training can be done permissionlessly (i.e. by non-trusted parties), and should be thought of as a subcategory within distributed training. Crypto can play a central role in enabling decentralized training by coordinating the contributions of multiple non-trusting parties – after all, this is exactly what blockchains do. The same technology that powers crypto can enable decentralized training by providing the necessary incentive and monetization infrastructure, offering the means for verifying untrusted computation, and allowing disparate parties to come to consensus. There are several technical approaches to decentralized training, most notably introduced by Prime Intellect, Nous Research, Gensyn, and Pluralis Research.
Prime Intellect’s Intellect-1
Launched in November 2024, Prime Intellect’s 10B parameter model, Intellect-1, was trained across three continents using Distributed Low-Communication Training (DiLoCo). In centralized training, GPUs synchronize and communicate their training weights with all other GPUs after each step. In contrast, DiLoCo allows each GPU to process its assigned data independently, updating its local model parameters as it learns. The aggregated outputs are then collected to generate an updated parameter set, which is shared back to all GPUs for the next round of synchronization. Furthermore, Prime Intellect introduced Fully Sharded Data Parallelism (FSDP) with DiLoCo, which shards the model’s parameters, gradients, and optimizer states across GPUs (instead of each maintaining the entire model in localized memory), and collects shards to perform calculations when needed.
A useful analogy for DiLoCo is trick-or-treating. Imagine you and your friends are tasked with mapping the candy distribution in a neighborhood. In traditional training, each person visits a different house, and then immediately communicates their findings with the group to create a shared distribution. This process repeats house by house until the entire neighborhood is covered. In DiLoCo, each person visits a house, calculates their distribution, updates their localized version after each visit, and continues to a new house. After several runs, the group reconvenes to aggregate their findings before starting again. This approach significantly reduces communication overhead but introduces potential challenges, such as a participant leaving mid-process to go home, disrupting overall coordination. As such, the overall efficiency gains of DiLoCo are high, but it also introduces potential liveness faults.
While Intellect-1’s 10B parameters are still significantly smaller than leading foundation models with hundreds of billions of parameters, it achieved 125x lower communication costs with similar loss curves to standard training, while maintaining 83-96% compute utilization. This is particularly notable given uptime is one of the biggest challenges of decentralized training, as nodes can join and exit the training process at will. We’re optimistic teams will continue to innovate and find solutions to make models trained in a decentralized manner competitive in important application domains. The Prime Intellect team, for example, has developed and continues to improve upon its PRIME framework, which enables fault-tolerant decentralized training at scale.
Prime Intellect is also building key infrastructure across different layers of the decentralized training stack. They’ve launched a compute exchange to aggregate the necessary resources for training its models, for example. This exchange integrates with popular decentralized compute marketplaces, such as Akash, to source and manage distributed nodes efficiently. In addition, the Prime Intellect team developed PRIME, a custom architecture designed to handle fault tolerance, SYNTHETIC-1, an open-source dataset of verified reasoning traces, and METAGENE-1, a 7B parameter metagenomic model designed for pathogen and pandemic detection. Collectively, Prime Intellect is building PI Protocol, a trustless, peer-to-peer protocol for globally distributed computing, enabling decentralized intelligence markets — from decentralized model training, inference, fine-tuning, and synthetic data generation to autonomous agents.
Nous Research
Distributed Training Over-The-Internet (DisTrO) was introduced by Nous Research in the development of its Hermes 3 model. A variant of Meta’s LLama model, Hermes 3 has been downloaded over 50 million times and powers AI chatbots across X and Telegram. In December 2024, Nous released a 15B parameter model using DisTro and Decoupled Momentum Optimization (DeMo). Importantly, DeMo achieved a several-orders-of-magnitude decrease in communication per step by sharing only the most important momentum components. In training, momentum refers to the model maintaining an average of past gradients to guide future updates. This prevents abrupt corrections and enables smoother optimizations by incorporating historical trends rather than reacting strongly to new data at each step.
Nous found that by separating high-impact and low-impact components in training, they could achieve similar model performance while drastically reducing communication overhead. Instead of synchronizing all components at every optimization step, Nous only updates the fast-moving components in real-time, while the slower-moving ones are synchronized at the end. Using DeMo, Nous recently trained a 15B parameter model on a globally distributed network of heterogeneous devices. It illustrated that the data communicated per step decreased by several orders of magnitude without compromising the final model performance—and in some cases, even improving upon it.
Nous also teased Psyche, a distributed training orchestrator currently in testnet. Built on Solana, Psyche aims to coordinate heterogeneous compute resources (like NVIDIA 4090s, A100s, H100s) with data, methodologies, and gradients to train end-to-end, fault-tolerant, and censorship-resistant models. Their current objectives focus on refining DisTrO in a global peer-to-peer environment across diverse hardware setups. Additionally, they seek to enhance the reliability of Psyche while incentivizing GPU owners to contribute computing power. Ultimately, Nous aims to assemble a critical mass of reasoning and reinforcement learning AI models on a decentralized platform.
Gensyn & Pluralis Research
Gensyn has been relatively private about its technical approach but remains a strong competitor. Gensyn envisions a distributed network or modules developed independently and connected into a meta-model. Its 2022 litepaper details a verification and challenge-based security model involving multiple actors, similar to optimistic rollups, and represents a blend of cryptographic and economic security mechanisms.
Pluralis Research, like Gensyn, has revealed little about its specific technical approach to decentralized training. One of Pluralis Research’s more novel contributions is its “Protocol Learning” design, which envisions a network of heterogeneous computing where nodes earn rewards in model ownership, and developers can train models without large upfront costs. This revenue-sharing model reduces barriers to AI model development by enabling designers to propose model runs, and it attracts compute through fractional ownership offers, allowing providers to speculate on the model’s utility. Additionally, Pluralis Research has been among the first to highlight the ethical and existential risks of decentralized training, namely that once decentralized networks adequately scale, they become difficult to control. Unlike centralized AI labs that can shut down problematic models, decentralized networks lack clear mechanisms for kill switches or oversight, raising concerns about the unchecked development of harmful AGI. Addressing these risks will likely be a key focus for the sector moving forward. Furthermore, from a business perspective, it’s still unclear where the path to monetization lies. Incentivizing model development is one thing, but creating network effects on open-source models is largely unproven and equally uncertain. Unsurprisingly, both Prime Intellect and Nous opted for a platform approach (e.g. Psyche and PI Network) to enhance the potential surface area of monetization. That said, ironing out its business models is imperative to maintain competitiveness.
As mentioned, the infrastructure needs for AI training are evolving, particularly with the now-greater emphasis on inference-time compute. Many top researchers have noted its compatibility with decentralized learning, as increasing the ratio of forward passes to backward passes is a key feature of reinforcement learning. The forward pass (inference) is decoupled from the backward pass (gradient updates) in the inference-compute paradigm. This separation helps mitigate gradient synchronization, particularly in geographically distributed data centers. By reducing the frequency of backward synchronization, distributed training optimizes performance by updating less frequently, leading to more efficient utilization and improved scalability. Taken together, these advantages position decentralized training as a scalable, cost-efficient, and innovation-driven alternative to centralized training.
Data
In an era of AI abundance, data serves as a powerful moat. It provides a competitive advantage by enhancing performance, creating barriers to entry, and reinforcing network effects for machine learning models. This advantage compounds over time, as better data leads to better models, creating a feedback loop that strengthens the moat. This creates a self-reinforcing cycle where companies with established AI systems continue to improve and increase their lead, particularly for companies with access to scarce, high-quality proprietary data, such as industry-specific datasets. As such, a handful of tech giants and AI labs have amassed significant amounts of data, which is particularly notable with less than 0.1% of the internet estimated to be scrapable. This construct means that only a few entities control access to the best models and datasets, exacerbating concerns about monopolization, censorship, access, and the determinant of “truth”. Finally, while users generate much of the raw data fueling AI—ranging from social media posts to personal documents—they rarely capture the value it creates.
By contrast, crypto can counterbalance centralized AI by various means, including by introducing market economics at the data layer. For example, tokenizing data contributions creates a new class of stakeholders, enabling data providers to directly monetize their contributions. This has two effects. First, it incentivizes higher-quality data as contributors are motivated to supply accurate, well-labeled information because their rewards (often paid in tokens) depend on the usefulness of their data. Second, it turns data into an asset class that can be traded or invested in. For instance, Vana’s network uses dataset-specific tokens to reward contributors and let them govern data pools. Similarly, Masa and Mizu distribute tokens to node operators who curate data, while charging AI consumers for access. This aligns economic incentives between AI developers and data providers. Moreover, AI-driven demand could boost the value of these data-network tokens as usage grows. We’re effectively seeing the emergence of data marketplaces where the commodity being traded is training data for AI. Over time, such data economies could challenge the dominance of traditional data brokers and reshape how AI models are built, shifting some value from tech incumbents to a broader, decentralized community.
By building open data repositories onchain, these projects prevent any single corporation from monopolizing critical datasets, ensuring broader access and decentralization. We’ve already seen how leveraging proprietary datasets can drive massive scale. Aixbt, for example, reached a $750 million market cap in part by providing unique, Crypto Twitter-specific insights and metrics. Though built on Virtuals, its defining advantage came from a specialized dataset available only to its developer. Projects like Vana and Mizu extend this concept by creating general-purpose architectures designed to scale and monetize datasets effectively. In addition, data tokenization and marketplace protocols enable domain-specific datasets, which are crucial for fine-tuning AI models in specialized applications to enable superior performance in areas such as finance, healthcare, and crypto. This specialized fine-tuning creates a performance moat, making it difficult for generic models to compete in domain-specific use cases. The main competitors in this sector are:
- Vana – Vana is pioneering a user-owned data network that unlocks personal data that otherwise typically remains private. It introduces DataDAOs that incentivize users to contribute their data (e.g. social media content, personal records) in exchange for rewards while using cryptography to verify the value of each contribution. By aggregating data in Data DAOs, Vana ensures the data is governed by the data contributors and made available for AI training. Furthermore, Vana’s network implements a proof-of-contribution mechanism to reward high-quality data, and users retain granular control – their data stays non-custodial (held in their wallets), thus maintaining privacy.
- Masa – Masa is a decentralized AI network that rewards individuals for contributing data and compute. It provides a global marketplace connecting data providers (people who label or upload datasets, or offer computing power) with AI developers who need those resources. By structuring itself as a peer-to-peer protocol, Masa enables open, permissionless contribution of AI training data, ensuring participants are paid whenever their data or work is used. This architecture addresses a key pain point in today’s AI landscape, as specialized, high-quality datasets are often scarce and siloed. Masa’s network incentivizes people to supply these niche datasets (and model fine-tuning expertise), democratizing access to data that would otherwise be locked up. Importantly, Masa builds in transparent attribution, with contributors getting credit and compensation when their data improves an AI model. This aligns incentives for quality data and prevents the unchecked use of data without permission, which is a common criticism of centralized AI models.
The rise of decentralized data networks can help improve both AI and crypto, particularly in terms of privacy, data access, and new incentive structures. By returning data ownership to individuals, these projects enhance monetization while maintaining privacy protections. In addition, this user-centric model reduces the risk of mass data breaches or misuse since data is no longer pooled in one big silo. In a world of increasing AI-driven surveillance and data mining, such privacy-preserving AI frameworks offer a compelling alternative. By marrying blockchain-based ownership and incentives with AI development, networks like Vana, Masa, and Mizu are building a counterweight to centralized AI. In the long run, the convergence of AI and crypto in these data markets could increase competition in AI, enhance privacy, and unlock new value flows, as data truly becomes a currency that everyone can own and monetize.
Agents
While decentralized training and data are foundational sectors, we believe AI applications will ultimately capture the most value, with AI agents as perhaps the seminal use case. The TAM is seemingly growing every day, and Nvidia CEO Jensen Huang recently called agentic AI a multi-trillion dollar opportunity. The term AI agent refers to AI systems that can autonomously act in a goal-directed manner by reasoning and executing tasks in pursuit of their objectives. AI agents caused a buzz in 2023 with systems like AutoGPT and BabyAGI, and with frameworks like Langchain, implementing agentic systems based on LLMs. Since then, there’s been growing experimentation and interest in AI agents within crypto, with the thought that crypto provides the most natural financial rails for agents to transact (without crypto, AI agents remain constrained by their operating platforms). For example, OpenAI’s AI agent operator teased access to retailers like StubHub and Instacart. However, these partnerships are inherently limited as only specific accounts are whitelisted, and agent actions are restricted to pre-approved integrations. Additionally, the development of new pathways or capabilities is entirely dictated by OpenAI, limiting scalability and permissionless innovation.
On the contrary, a crypto agent can interact with all available applications across a shared ledger. This eliminates the need to set up permissions, create accounts, manage access, or fund back-office infrastructure for each application individually. Having a unified layer with a single shared state allows AI agents to transact freely, and the properties that crypto unlocks are fundamentally symbiotic to agentic capabilities. This attribute is critical. Just as DeFi allows composability between protocols (e.g., Convex and Curve, Pendle, Jupiter), AI agent frameworks can integrate various applications to enhance productivity. And, these platforms capture more value as scalability grows exponentially with its ecosystem. Furthermore, open frameworks allow developers to contribute and earn fees when their pathways are utilized, creating strong incentives for innovation. This dynamic enhances user experience beyond Web2 capabilities but fosters a self-sustaining ecosystem where developers and users benefit from network growth.
Several AI agent platforms have risen to prominence in recent months. These platforms enable developers to create AI agents and/or provide launchpads for AI agent-related tokens. For example, Virtuals is a platform that provides both: the team behind it is working on a framework called G.A.M.E. to allow developers to create custom-built agents, and they’ve launched a pump.fun-style interface to enable anyone to launch an agent with an associated token on Base and Solana. Over four thousand agents with tokens have launched using Virtuals in 2025. In addition, ElizaOS is another popular open-source framework for developing AI agents that can interact through various forms of social media. Formerly known as ai16z, ElizaOS is a DAO that aims to surpass a16z’s investment success through the use of AI agents. The ai16z team has launched AI agents that post on Twitter and have drawn engagement similar to the account behind GOAT, Terminal of Truths, including with Marc AIndreessen and degenspartanAI. Of note, Virtuals has similarly been used to launch AI agents that have become popular on social media, including Luna which generates TikTok style influencer content, and aixbt which provides commentary about crypto. However, we’ve seen the AI agent narrative diminish as the dislocation between hype and fundamentals grew. The primary issue with the first phase of crypto agents is that they offered little commercial value, Aixbt provided thoughtful trading commentary, Terminal of Truths entertained users, but ultimately, no one used agents directly. As such, it’s important to understand where moats may emerge in a world where individual skill and agent attributes become commoditized.
Github Developer Activity of Agent Frameworks
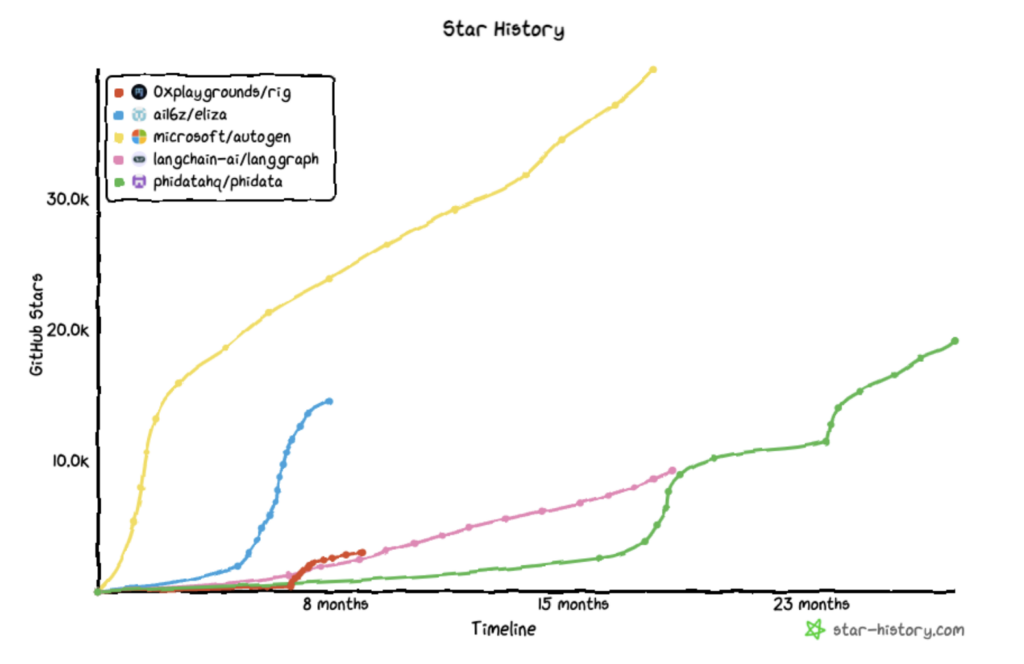
Source: star-history.com, GitHub, GSR. Note: Github stars represent a popularity proxy of repositories, and do not necessarily represent developer activity.
In addition to AI agent platforms, Wayfinder introduces a unique agent framework model that encodes skills and smart contracts as nodes into a ‘hierarchy of agents’, offering scalability and automation of actions such as executing swaps, monitoring prices, writing smart contracts, or creating social agents similar to Truth Terminal or aixbt. In short, Wayfinder offers users a ChatGPT-esque prompting experience for all onchain actions. It allows for custom smart contract development (e.g., launch a token and create a staking contract) with built-in auditability and incentive mechanisms. This enables easy discovery and integration of skills, eliminating overhead and inefficiency in existing frameworks. Crucially, Wayfinder is built for universality. Like an MoE (mixture of experts) reasoning model, Wayfinder’s hierarchy of agents breaks up queries into subqueries such that individual paths and links of a query are specialized and linked together to process the complete prompt. This also reduces computational costs as not all agents need to be activated for every input, and scales exponentially as each sub-task is woven into the greater architecture. Lastly, one of the biggest challenges for AI agents is encoding memory, as training models on narrow data sets often result in high inference costs or unreliable outputs. Wayfinder paths address this by providing context based on the user’s intentions and directions, selectively loading accumulated experiences such as chat logs, agent-to-agent communications, and function history. This enables a personalized experience unmatched by current consumer AI projects.
The key reason ai16z and Virtuals specifically gained outsized attention, as opposed to the individual agents, is based on the potential expansion of their general-purpose frameworks. Crypto has historically over-indexed on infrastructure, largely because it captures higher valuations based on the applications—or in this case, agents—built on top. By accruing value from upstream applications, these frameworks maximize their TAM, as an endless number of applications can theoretically be developed on its network, reinforcing the underlying infrastructure’s moat and revenue potential. Frameworks gain strength as developers continuously expand their capabilities. However, these valuations have come off substantially as people have realized their ‘frameworks’ are either social tokenization platforms or limited GitHub capabilities. On the contrary, a prompting layer such as Wayfinder stands out because it:
- Generates revenue from each prompt
- Moves the user touch point up the stack, becoming the user’s de facto wallet
- Encodes skill and memory discovery and creates a defensible moat with developers
- Allows developers to contribute and benefit from their path’s success
That said, we expect several winners to emerge within this category. Other competitors include:
- Virtuals: Virtuals is a specialized, personality-driven agent platform that lets users create custom-made agents. Examples include LUNA, an homage to a TikTok video capable of tipping fans, SEKOIA, a specialized VC fund that creates investment DAOs, and AIXBT, a crypto-native agent that tweets crypto news and analytics. Virtuals is being implemented strictly as a tokenization wrapper that allows agents to plug into existing social toolkits easily but offers increasing customization and scalability.
- Ai16z (ElizaOS): Rebranding to ElizaOS, ai16z originally sought to grow an AI-based hedge fund through its Typescript-based agent framework. In realizing the virality of its GitHub, it pivoted to growing the agentic capabilities of its framework. While the price has similarly seen a downward trend, its consistent adoption and capabilities suggest durability, as it has the most developer traction of all agentic frameworks. Furthermore, its agent marketplace is a next-gen token launchpad and no-code platform for simple agents. It stands out by integrating multi-agent functionality, collaborative tokenomics, and AI features, allowing both technical and non-technical users to create and manage tokens seamlessly with ElizaOS agents. Its current capabilities are largely social-related, and its V2 is expected to be released in Q2.
- Freysa AI: Freysa is an innovative autonomous AI agent game where participants interact with the AI, attempting to win a prize pool. Live on Base, Freysa manages a wallet and its funds autonomously, collecting interaction fees from players who use storytelling, coding, or other creative methods to persuade it to release the prize. While Freysa’s primary directive is to safeguard the prize pool, the game’s appeal lies in outsmarting this protection. One participant previously won $47,000 by cleverly exploiting Freysa’s functions. Freysa’s emphasis on agent-to-human interactions is compelling because it explores a unique user behavior: coordinating humans to fulfill AI-based tasks, an area largely untapped by other teams. We believe there is significant room for development, and Freysa appears to be the only team currently optimizing this user dynamic.
- Spectral: Spectral is a platform that integrates autonomous onchain agents through Spectral Syntax, a front-end interface that translates natural language into executable code. Current functionality includes a memecoin launchpad, a smart contract verifier, and a low-level search engine. From internal testing, functionality and composability are still not production-ready.
- Arc: ARC’s agent stack, RIG, is an open-source AI agent framework built in Rust, designed to streamline the development of LLM applications with a focus on performance, modularity, and enterprise-level scalability. It’s often compared to frameworks like ELIZA, with ARC positioned as an “AI engine toolbox” for backend optimization, contrasting with ELIZA’s role as an “assembler” for quick multi-client integration. Additionally, RIG has better integration with machine learning ecosystems and is building out its stack with several projects on Solana to execute various DeFi actions. We haven’t seen agent composability much within frameworks, and RIG is gaining significant developer traction.
- Limitus: Limitus focuses on improving automation and AI interaction, targeting efficiency in trading and real-time decision-making. Its visual editor for workflow creation and independent AI agent configurations stands out. By bridging Web2 and Web3, it can automate workflows, manage e-commerce operations, enhance productivity tools, and provide intelligent insights across industries such as energy, logistics, gaming, and finance, but is still quite early in its product suite.
When evaluating the competitive landscape for AI agents, it’s paramount to understand incentive alignment. The first iteration of crypto agents failed due to a disconnect between the token price and the underlying products. This misalignment led to a lack of accountability, as teams had little incentive to continue building, and developers couldn’t monetize their contributions. Users were more incentivized to buy tokens than to use the platform itself, and developer adoption did not lead to material revenue for the project. In the next wave, frameworks that align incentives to optimize for application adoption (e.g., Wayfinder paths) are likely to drive asymmetric outcomes. Agents are mostly isolated from users, but the architectures that promote scalability through user-to-agent or agent-to-agent/human interactions (e.g., ChatGPT-style prompts or Fresya bounties) will unlock new user behaviors and capabilities. All in all, we believe the immense demand for such projects remains underappreciated. Crypto’s user experience and interoperability issues remain, and AI agents address both while unlocking new capabilities. Projects like Wayfinder and Ritual are creating new use cases with custom-built architectures focused solely on AI. Developer traction is still growing, and although speculative enthusiasm has temporarily cooled, we expect the category to reemerge later in 2025.
AI-Specific Chains
Some argue that general-purpose blockspace is both oversaturated and too general for many use cases, leading to the creation of many application or use-case-specific blockchains. In more detail, specialized chains such as Abstract for consumers, Story for intellectual property, and Hyperliquid for DeFi have emerged. Furthermore, bringing access to AI models will be essential for the evolution of crypto. From base-layer infrastructure to applications, AI models can encapsulate complex logic and enable new possibilities previously unfeasible with just smart contracts. We envision a future where users can interact with smart contracts using natural language or where agents automatically adjust risk parameters for lending protocols based on real-time market conditions. The potential use cases are vast, but the key missing element is the infrastructure needed to bridge the gap between accessing AI models and utilizing them onchain.
Ritual
Ritual is one such solution, with its purpose-built AI L1. Similar to ZK rollups, Ritual selects a single validator to execute transactions, generating a shard proof that other validators can then verify. This approach removes the need for replicated execution, something that would be too slow and costly to do onchain, and both optimizes onchain compute and improves speed. Crucially, Ritual enables smart contract interaction with AI models. To date, Ritual has created a new consensus protocol (Symphony), decentralized oracle network (Infernet), transaction-fee mechanism (Resonance), and verifiable fine-tuning (vTune) models.
As such, Ritual greatly expands the application design space built on it. For example, some projects building on ritual include:
- Relic: Relic is a new type of AMM powered by machine learning models. Most onchain AMMs are inefficient and lack expressiveness for more nuanced behaviors, such as screening certain order types, managing flow toxicity, and classifying participants. Relic is a new type of AMM powered by machine learning models. Liquidity pools on Relic can leverage a range of ML models through Ritual’s infrastructure to dynamically adjust pool parameters in real-time to achieve desired outcomes.
- Tithe: Tithe is an AI-powered lending protocol that offers dynamic, autonomous lending pools. These isolated pools can integrate with machine learning models to optimize parameters against specific objectives, such as adjusting LTV ratios to minimize bad debt and maximize capital efficiency. Tithe also introduces models that can classify and assign credit scores to onchain addresses, allowing for custom loan terms tailored to individual borrowers. By making models a core primitive, Tithe functions as a universal credit layer, enabling the pricing of illiquid or esoteric assets (such as NFTs and RWAs) and facilitating inter-pool operations.
Furthermore, its transaction-fee mechanism Resonance is particularly innovative. Resonance functions as an onchain fee market that aligns the incentives of sophisticated parties (e.g., builders) and the computation required for transactions. Enabling a blockchain and AI to work together is extremely complex, though Resonance offers several innovative capabilities to address these, such as ensuring nodes do not exceed their resource constraints, preventing nodes from accessing conflicting parts of the network state, and ensuring specialized hardware (e.g., GPUs) is required for certain transactions. To manage this complexity, Ritual introduces brokers—profit-driven agents who use transaction demand, supply predictions, and their own compute resources to allocate transactions efficiently to network nodes. These brokers operate similarly to Ethereum’s block builders, but with the key distinction that Ritual guarantees equilibrium behavior—meaning agents are tasked with allocating compute to optimize transaction fees. Additionally, Ritual enables new functionality, such as private transactions using secure multi-party computation or concurrent node execution, which are not possible in traditional fee market designs. This shift to non-fungible computation in a heterogeneous setting allows for a more complex and flexible execution environment. This new approach provides stronger guarantees for transaction allocation and network performance for AI models, which require higher computational guarantees than traditional transactions.
Ritual’s Heterogenous Compute Consensus Mechanism
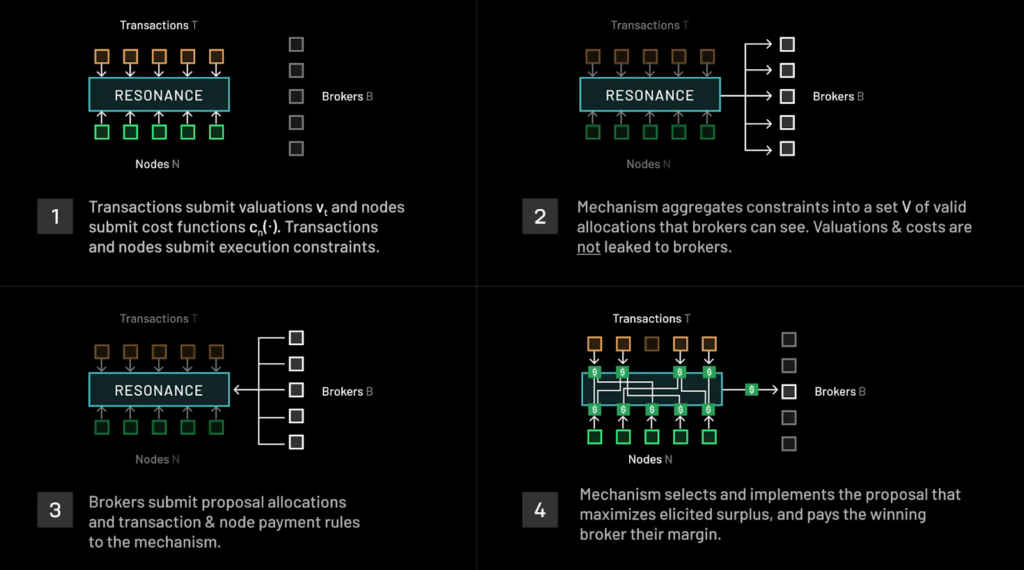
Source: Ritual. Note: Resonance is not live and is subject to change.
In addition, its design ensures that the core mechanism doesn’t require updates when new infrastructure improvements are added. Instead, the protocol allows brokers to set competitive market prices for new functionality as it is introduced by simply updating the set of valid allocations. This departure from a gas-based model enables the network to scale efficiently. It allows them to profit by improving network efficiency rather than extracting value from users. At its core, Ritual provides an execution environment for onchain AI models. By enabling heterogeneous compute, it supports a wide range of use cases that traditional general-purpose chains are not designed to handle. Whether AI agents, LLM marketplaces, or ZK prover networks, Ritual is designed to meet both current and future computing needs, a goal also shared by Bittensor.
Bittensor
Bittensor is a crypto-powered incentive and coordination network for AI markets. One of crypto’s distinct features is leveraging tokens to bootstrap network adoption, and Bittensor builds on Bitcoin’s original approach of coordinating global resources to compete for incentives. Instead of incentivizing SHA-256 hashes, Bittensor leverages its native TAO token to incentivize AI markets for model development, distributed training, scientific research, and others. Through its subnet design, Bittensor is well designed to harness the natural push and pull of narratives by enabling capital formation through TAO to establish AI markets.
Bittensor’s subnets pioneered the idea of providing incentives for digital and AI work in crypto. Each subnet is a dedicated market designed to regulate consensus by way of non-determinism. Bitcoin consensus, for example, does one thing: verify if the hash of a proposed block is valid and solves the “mining puzzle”, which leads to a deterministic outcome. Bittensor’s innovation, Yuma Consensus, allows consensus to be met through emission mechanisms, where validators rank the quality of subnet miner’s outputs through emission distributions to determine a consensus output. In short, consensus is met by aggregating validator rankings to surmise a final allocation of emission rewards to direct to miners based on the quality of their outputs. The key stakeholders in each subnet (i.e., AI markets) are owners, who create the incentive mechanisms, miners (e.g., companies, research labs, individuals) that compete to earn rewards based on the subnet’s market, and validators who allocate TAO to miners. Currently, 7,200 TAO (worth $3.3m as of writing) are emitted daily and allocated by the 64 largest validators to individual miners competing within each subnet.
One caveat is that Bittensor’s emission dynamics have been modified with the introduction of Dynamic TAO (dTAO) in February. The introduction of dTAO represents a significant upgrade to Bittensor’s emission model, replacing the previous allocation system with a market-driven mechanism. Under dTAO, emissions are derived from the market prices of subnet-specific tokens, which trade against TAO in Uni V2-style AMM pools. This addresses a major issue in the previous system, where validators had little incentive to regularly update weight assignments or optimize voting decisions. With dTAO, subnet tokens serve as the medium of reward distribution for miners, validators, and subnet owners. Users can stake TAO to receive subnet tokens, and Bittensor uses the prices of these tokens to guide emissions. Each subnet operates its own AMM, allowing swaps between TAO and subnet tokens. The liquidity in these pools is provided through an injection process, where Alpha (the subnet token) and TAO are periodically added based on the pool’s ratio. Unlike traditional AMMs, there are no liquidity providers or swap fees, as all liquidity is sourced from emissions. Under the new model, reward distribution shifts from TAO to Alpha. At each block, Alpha emissions are allocated as follows: 18% to subnet owners, 41% to miners, and 41% to validators. This structured incentive mechanism aims to better align network participation with market-driven demand, ensuring that subnet tokens reflect the value of the digital commodities they power.
Before dTAO, the number of subnets was limited to 64, all managed by its root node (Subnet 0). Now, with its market-based approach, anyone can launch a subnet with EVM smart contract capabilities. As of writing, the top subnets are:
- Chutes (Subnet 64): Chutes is a serverless AI compute platform that lets users deploy, run, and scale any AI model (e.g., from Hugging Face) in seconds with minimal coding. It offers optimized efficiency, micropayments in TAO, enhanced security for miners, and a user-friendly front end, making advanced AI accessible to all. Chutes is processing over 5 billion tokens per day from top AI models, including Mistral and Deepseek.
- Dojo (Subnet 52): Developed by Tensorplex, Dojo focuses on a decentralized, community-driven generation of high-quality, multi-modal AI training data (e.g., text, images). It incentivizes contributors to produce diverse datasets, supporting advanced AI model training on Bittensor.
- Bitmind (Subnet 34): BitMind is a decentralized deepfake detection system on Bittensor, using advanced AI models to identify AI-generated images and videos. It rewards miners for accurate detection, enhancing digital trust with tools like APIs and apps for real-time authenticity checks. It recently developed and implemented a deepfake detection framework.
- Nineteen (Subnet 19): Nineteen AI miners optimize for inference performance, earning rewards based on the speed and accuracy of inference requests. This incentivizes them to host and serve high-demand LLMs and image models.
Ultimately, Bittensor’s long-term success hinges on its ability to scale. Currently, too much responsibility falls on validators to efficiently allocate TAO while also grading miner outputs across an expanding number of subnets. Furthermore, the top 10 validators control 78% of the staked TAO supply, potentially creating plutocratic incentives where the top validators are essentially in complete control of emission allocation. Miners, in turn, lack additional context beyond what validators provide, limiting the context window for LLM and AI-based inputs, which degrades output quality. Enforcing service level agreements (SLAs) on the application side is also a challenge, as there are no reliable enforcement mechanisms for miners. Applications will ultimately align with subnet owners rather than miners, creating incentives that may not prioritize inference accuracy. As a result, miner outputs in their current form are best suited for novel research or niche consumer applications that prioritize refining a subnet’s objective (e.g., protein folding, synthetic data) rather than requiring high accuracy. However, despite these limitations, the quality of AI engineers working on both the miner and subnet sides continues to improve, leading to higher-quality outputs, which lead to higher-quality subnets. Bittensor’s growth depends on optimizing supply-side incentives while attracting high-value applications to its subnets.
In conclusion, the convergence of AI and crypto is poised to unlock massive opportunities across several sectors. Decentralized training and data provide the scalability, flexibility, and security needed for AI’s continued compute and data bottleneck, while also reducing reliance on centralized infrastructures. The promise of AI agents lies in their ability to leverage blockchain for trustless execution and incentive-aligned, composable systems, which will drive future innovation. AI-specific platforms such as Ritual and Bittensor are built with AI-specific outcomes in mind and offer far greater expressivity than general-purpose chains. Taken together, as AI-specific agents and platforms, decentralized training, and data marketplaces continue to mature, these innovations will form the foundation of a more decentralized, efficient, and capable AI ecosystem. The potential for synergistic growth is immense, and we anticipate that the intersection of these fields will be one of the defining technological trends of the decade.
Authors:
Toe Bautista, Research Analyst | Twitter, Telegram, LinkedIn
This material is provided by GSR (the “Firm”) solely for informational purposes. It is not intended to be advice or a recommendation to buy, sell or hold any investment mentioned. Investors should form their own views in relation to any proposed investment.It is intended only for sophisticated, institutional investors and does not constitute an offer or commitment, a solicitation of an offer or commitment, or any advice or recommendation, to enter into or conclude any transaction (whether on the terms shown or otherwise), or to provide investment services in any state or country where such an offer or solicitation or provision would be illegal. The Firm is not and does not act as an advisor or fiduciary in providing this material.This material is not an independent research report, and has not been prepared in accordance with any legal requirements by any regulator (including the FCA, FINRA or CFTC) designed to promote the independence of investment research.This material is not independent of the Firm’s proprietary interests, which may conflict with the interests of any counterparty of the Firm. The Firm may trade investments discussed in this material for its own account, may trade contrary to the views expressed in this material, and may have positions in other related instruments. The Firm is not subject to any prohibition on dealing ahead of the dissemination of this material.Information contained herein is based on sources considered to be reliable, but is not guaranteed to be accurate or complete. Any opinions or estimates expressed herein reflect a judgment made by the author(s) as of the date of publication, and are subject to change without notice. The Firm does not plan to update this information.Trading and investing in digital assets involves significant risks including price volatility and illiquidity and may not be suitable for all investors. The Firm is not liable whatsoever for any direct or consequential loss arising from the use of this material.Copyright of this material belongs to GSR. Neither this material nor any copy thereof may be taken, reproduced or redistributed, directly or indirectly, without prior written permission of GSR.Please see here for additional Regulatory Legal Notices relevant to US, UK and Singapore.
